
Gemini 3は、Googleによって開発されたこれまでのAIの常識を覆す次世代の人工知能モデルです。日本では、2025年11月19日よりGeminiアプリやブラウザ版・Google AI Studioなどで利用できるようになりました。

大量のデータからパターンを学び、人間のように自然な応答や創造的な出力を行う技術(大規模言語モデル / LLM)の最新モデルとして注目を集めています。
従来のAIとの決定的な違いは、あらゆる情報を同時に処理できる能力(マルチモーダル能力)を最初から持っている点にあります。
この「マルチモーダル能力」とは、文字(テキスト)だけではなく、画像、音声、動画、コードなど、異なる形式の情報をすべて一体として理解し、関連付けて処理できるということを意味します。
たとえば「この写真の内容を音声で説明しながら、その情報を元に新しい詩を書いて」といった複雑な指示も、AIが途切れることなくスムーズに実行できます。
本記事では、Gemini3 Proの具体的な使い方にフォーカスして詳しく解説します。
Gemini 3 Proは無料で利用できる
Gemini 3 ProはGeminiアプリやGoogle AI Studioにて無料で利用できます。
Geminiアプリやブラウザ版では、Googleアカウントでログインし、チャットの仕様を「Fast」から「Thinking」へ変更するだけで利用可能です。
Google AI Studioでは、Gemini 3はもちろん、これまでに登場したほかのバージョンも利用できます。
「とりあえずGemini 3を触ってみたい」という方はGeminiアプリやブラウザ版で早速試してみましょう。
Gemini 3とどれだけ性能が異なるのか比較したい方は、Google AI Studiohが適しています。
Gemini 3 Proの何が凄いのか?
Geminiの突出した能力は、単なる技術力の向上に留まらず、私たちの日常的な作業を根本的に変える可能性を秘めています。
その核となる凄さは、主に以下の3つの領域で具体的に示されています。
際立つ思考力と学術的推論能力
Gemini 3 ProはAIベンチマークの最高峰である「Lasting Humanity’s Exam」において現行モデル最高のスコアを達成しました。
このベンチマークは、専門知識と論理的思考を問う極めて難解な問題集であり、この高いスコアは、Geminiが抜きん出た学術的な推論能力を持っていることの具体的な証明となります。
飛躍的な画像・手書き認識能力
文字から画像を認識する能力が大幅に向上し、特に手書き文字の認識精度が驚異的です。
例えば判読が難しい手書きの日記でも、従来のモデルが壊滅的だったのに対し、Geminiは意味が完璧に通じる内容で文字起こしを成功させました。
これにより高精度な文字起こしが可能になり、私たちの入力作業を大きく変えつつあります。
革新的なデザイン構築力
AIのデザイン能力を評価する「Design Arena」で圧倒的な高評価を獲得しています。
X上では、洗練されたデザインのサイトを瞬時に生成できるとのことで話題となっています。
また、複雑なワークフローツールの練習ゲームなども、一つのプロンプトから細かいアニメーションまで含めて作成できるなど、その表現力はプロの品質に近づいています。
Gemini 3の特徴
| 項目 | 内容 |
|---|---|
| モデル | ・Gemini 3 Pro ・Gemini 3 Deep Think(推論強化モード) |
| 特徴 | ・最先端のマルチモーダル理解と推論性能 ・エージェント・コーディング能力の強化 |
| 主な用途 | ・学習支援 ・情報整理 ・Web UI生成 ・ゲームやコード生成 ・エージェント実行など |
| 代表的ベンチマーク | ・LMArena ・Humanity’s Last Exam ・GPQA DiamondなどでSOTA級 |
| コンテキスト | 最大100万トークンのコンテキストウィンドウ(長文・長時間コンテンツの取り扱いに対応) |
| 提供開始 | 2025年11月より順次提供開始 |
| 提供チャネル(個人向け) | ・Geminiアプリ ・AI Mode in Search(Google AI Pro / Ultraなど) ・Gemini Agent(Google AI Ultra向け) |
| 提供チャネル(開発者向け) | ・Gemini API(AI Studio) ・Google Antigravity ・Gemini CLI ・Vertex AI ・サードパーティIDE/プラットフォーム |
| 安全性対応 | ・包括的な安全評価 ・プロンプトインジェクション耐性強化 ・サイバー攻撃悪用対策 ・シンカシー(迎合的態度)の低減など |
Gemini 3 Proの使い方
Gemini 3をGeminiアプリやブラウザで使う方法と、Google AI Studioで使う方法について解説します。
Gemini 3をGeminiアプリやブラウザで使う方法
はじめにGeminiアプリやブラウザにアクセスします。


Geminiにログインしていない方は、右上にある「ログイン」をクリックしてアカウント認証しましょう。
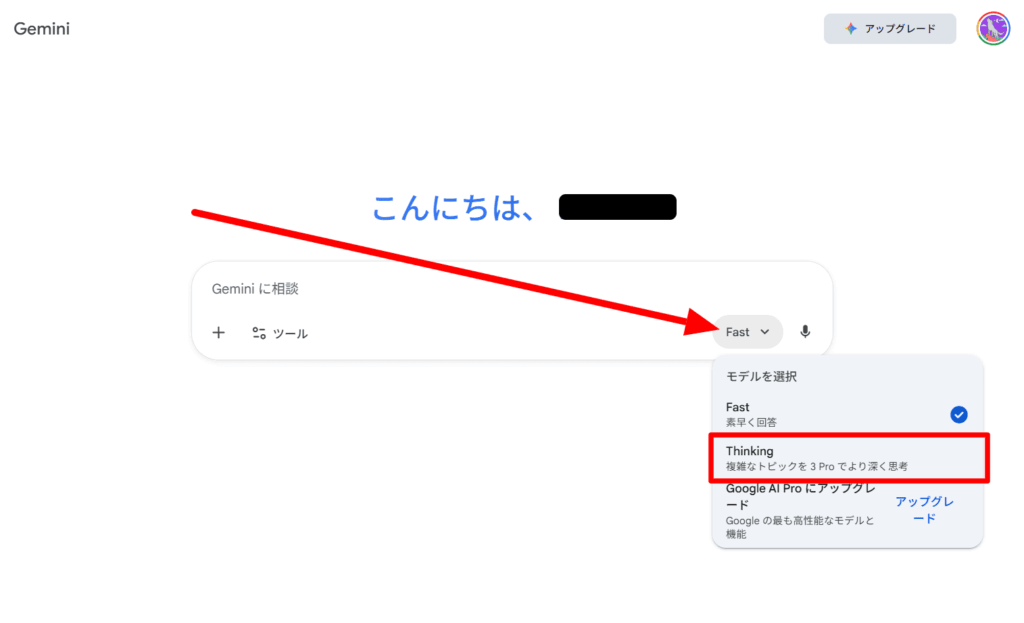
するとGeminiのチャット画面が表示されます。右下にある「Fast」をクリックすると、表示内容から「Thinking」というGemini 3 Proを選んで実行できます。
このように、Geminiアプリやブラウザを使えば、誰でも簡単にGemini 3 Proを利用できます。
Google AI StudioでGemini 3 Proを使う方法
はじめにGoogle AI Studioへアクセスします。

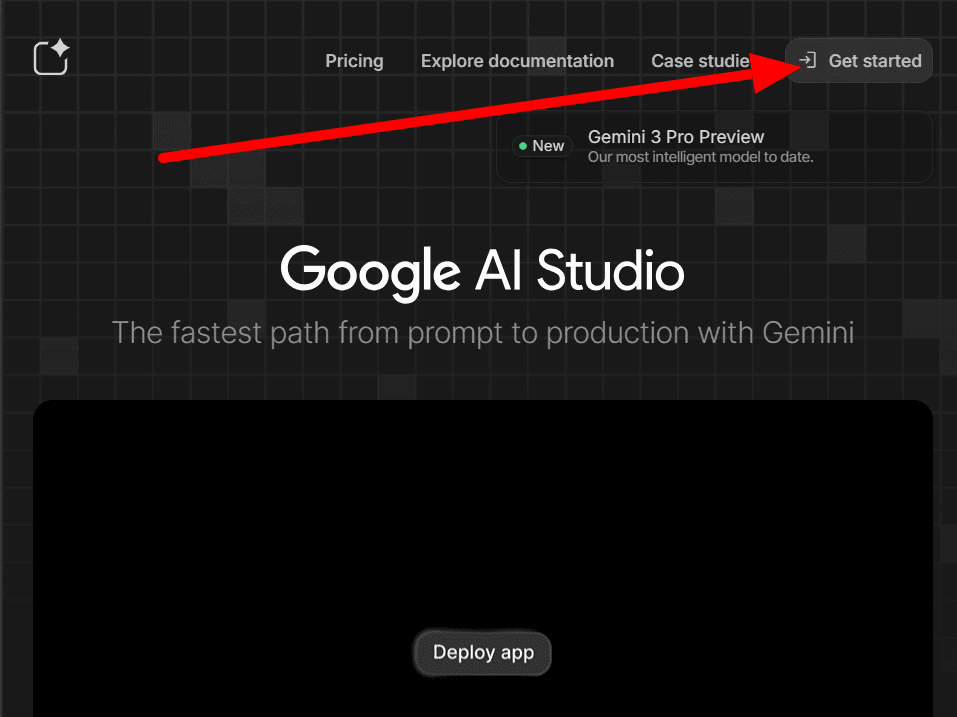
トップページの右上にある「Get started」をクリックします。
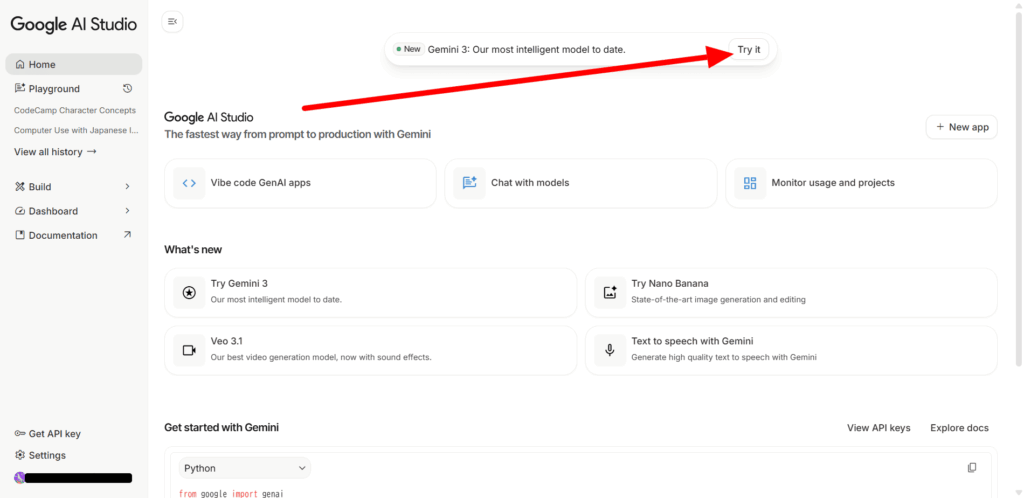
Googleアカウントで認証を終えたら、上記のような画面が表示されます。右上のチャット欄にGemini 3を始める表記があるので「Tri it」をクリックしましょう。
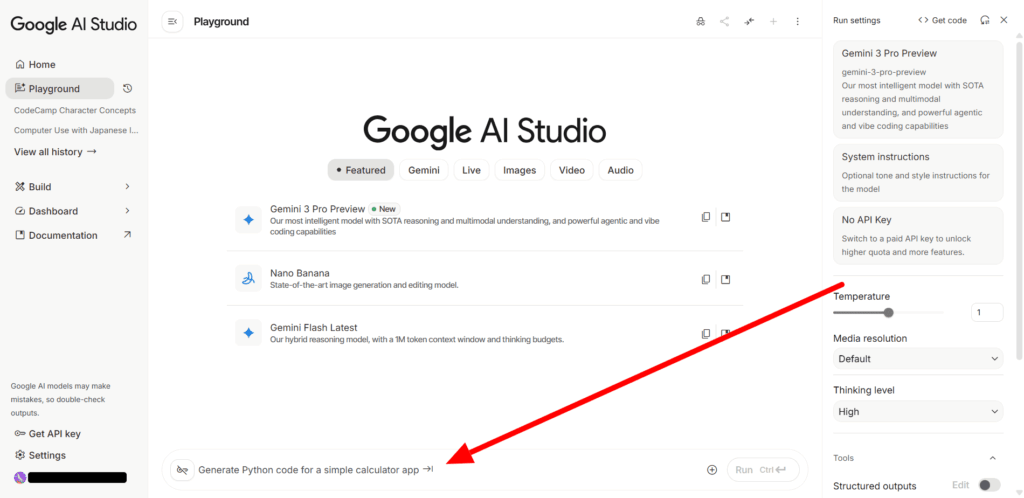
すると、画面下部にチャット欄が表示されるので、ここにテキストを入力して「Run」をクリックすることでGemini 3とチャットを始められます。
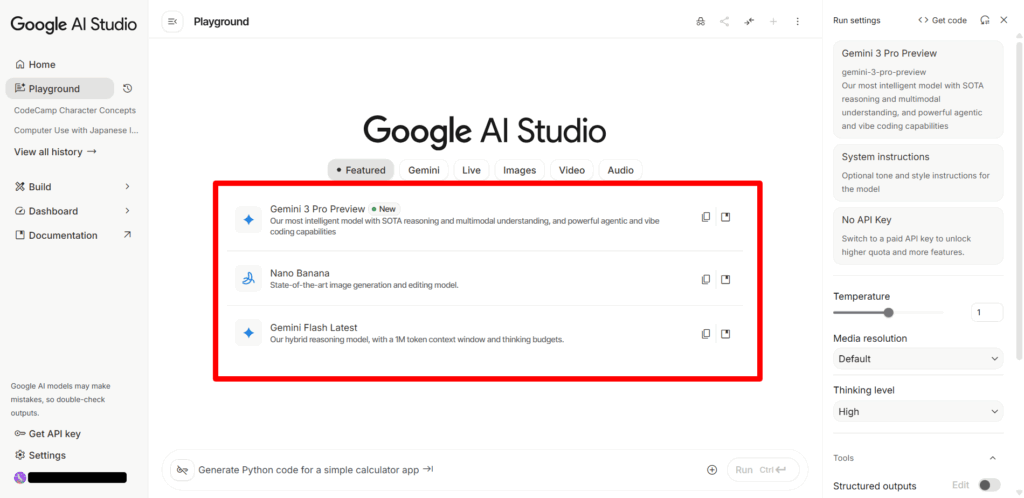
なお、Gemini 3以外にも、画面中央にあるGemini 3 ProやNano Bananaなどのバージョンやモデルも利用可能。使いたい部分をクリックし、下のチャット欄にプロンプトを入力するだけで利用できます。
Gemini 3 Proと以前のバージョンの違いを画像生成で試してみた
Geminiで画像を生成する際は「Nano Banana」というモデルを使っており、現状、Gemini 3 Proになってもこれは変わりません。
しかし、Gemini 3 Proになったことでテキストや画像への理解度がアップしているので、これまでのGemini以上にプロンプトに忠実な画像ができるのではないかと思いました。
そこで、以前Geminiで作った画像と同じ指示をGemini 3 Proに送って出力結果を比較してみます。
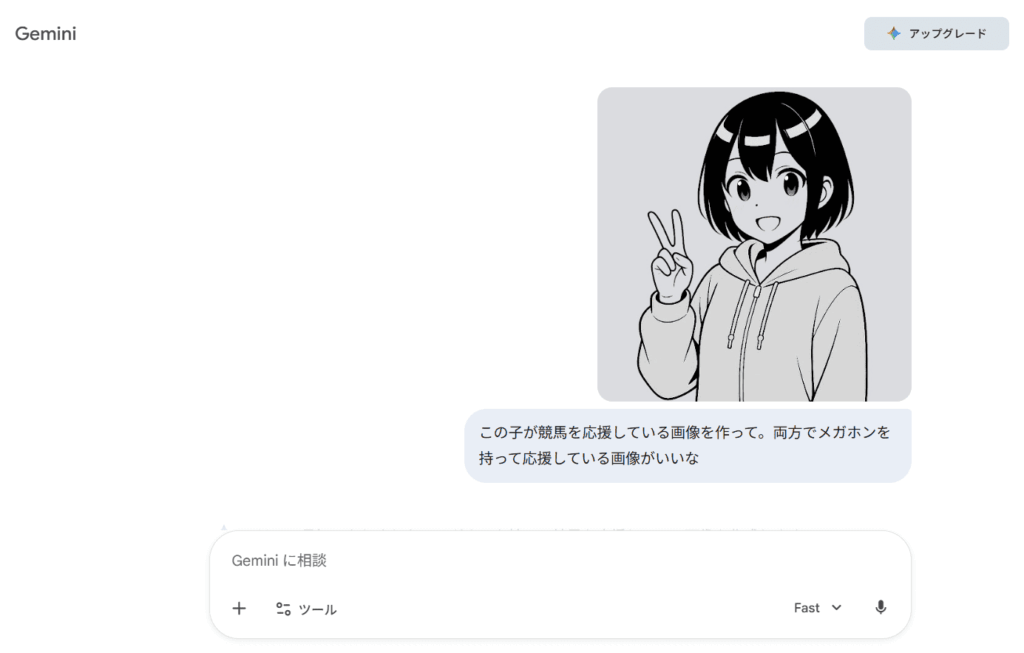
今回は、上記の画像とプロンプトをGeminiに送り、モデル別の出力結果を比較します。
【出力結果】
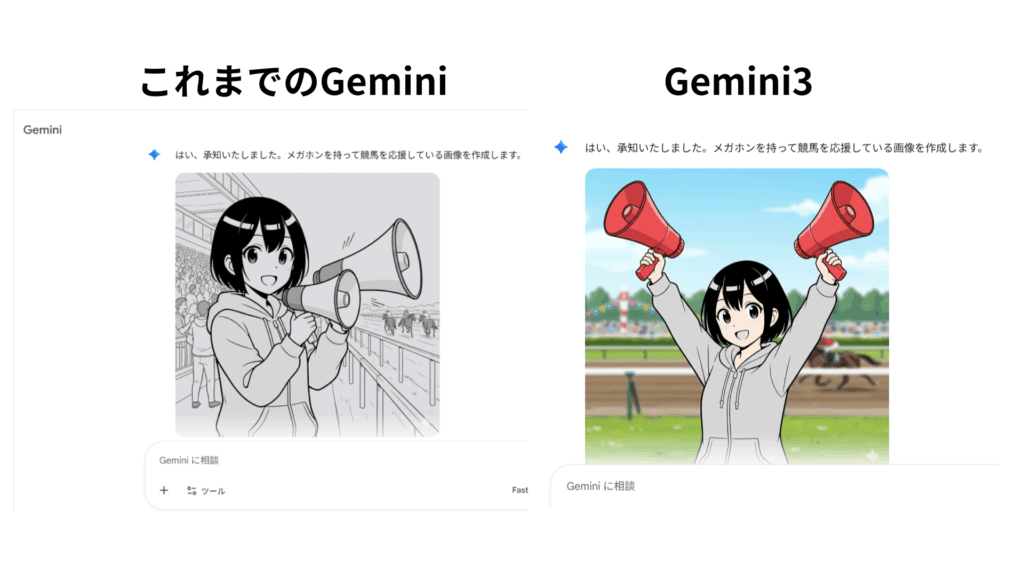
これまでのGeminiで静止した画像も高品質ですが、メガホンが重複しているように見えるのが少し気になりますね。
Gemini 3の方もメガホンは2つ表示されていますが、両手している部分も含めてこちらの方が品質は良さそうです。ただし、アニメ調の被写体とリアルに近い背景にギャップがあるので、そこは気になるところです。
強いて言えばGemini 3の方が品質は良さそうですが、大きな違いはないことがわかります。
結局プロンプトを詳細に設定すればどちらも実用的な画像を生成できそうです!


コメント